LLM이란 무엇인가?
대규모 언어 모델(Large Language Model)은 주어진 텍스트 다음에 올 단어를 예측하는 정교한 수학적 함수입니다. 정확히는, 다음에 올 단어들의 확률 분포를 계산하여 가장 그럴듯한 단어를 선택합니다.
대규모 언어 모델(Large Language Model)은 주어진 텍스트 다음에 올 단어를 예측하는 정교한 수학적 함수입니다. 정확히는, 다음에 올 단어들의 확률 분포를 계산하여 가장 그럴듯한 단어를 선택합니다.

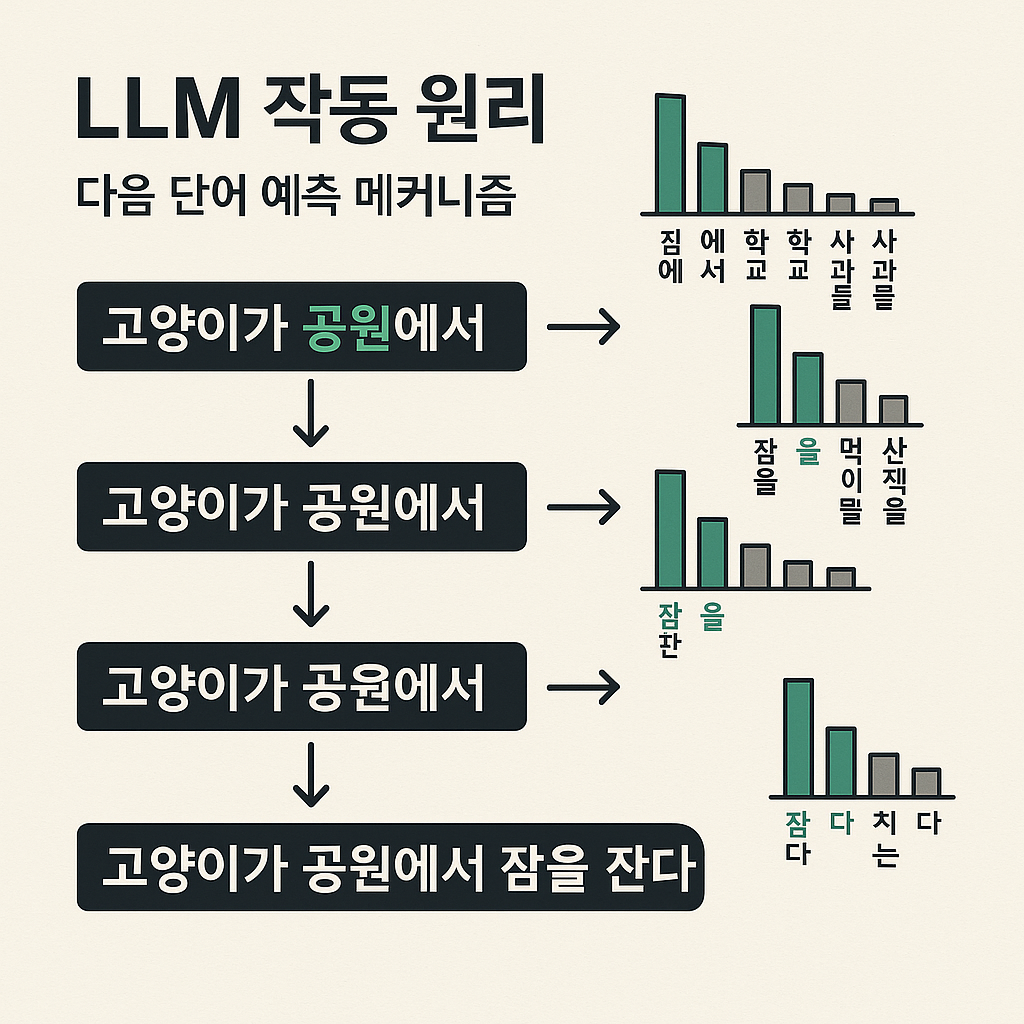
LLM은 한 단어씩 다음에 올 내용을 생성합니다. 사용자 질문에 대해 AI가 반응할 단어를 예측하며, 때로는 확률이 낮은 단어를 선택하여 더 창의적이고 자연스러운 답변을 만듭니다.
LLM은 방대한 인터넷 텍스트로 학습됩니다. 훈련은 텍스트의 다음 단어를 예측하고, 정답에 가깝도록 모델의 파라미터(가중치)를 미세 조정하는 과정을 반복합니다. 이 과정에서 역전파(Backpropagation) 알고리즘이 사용됩니다.

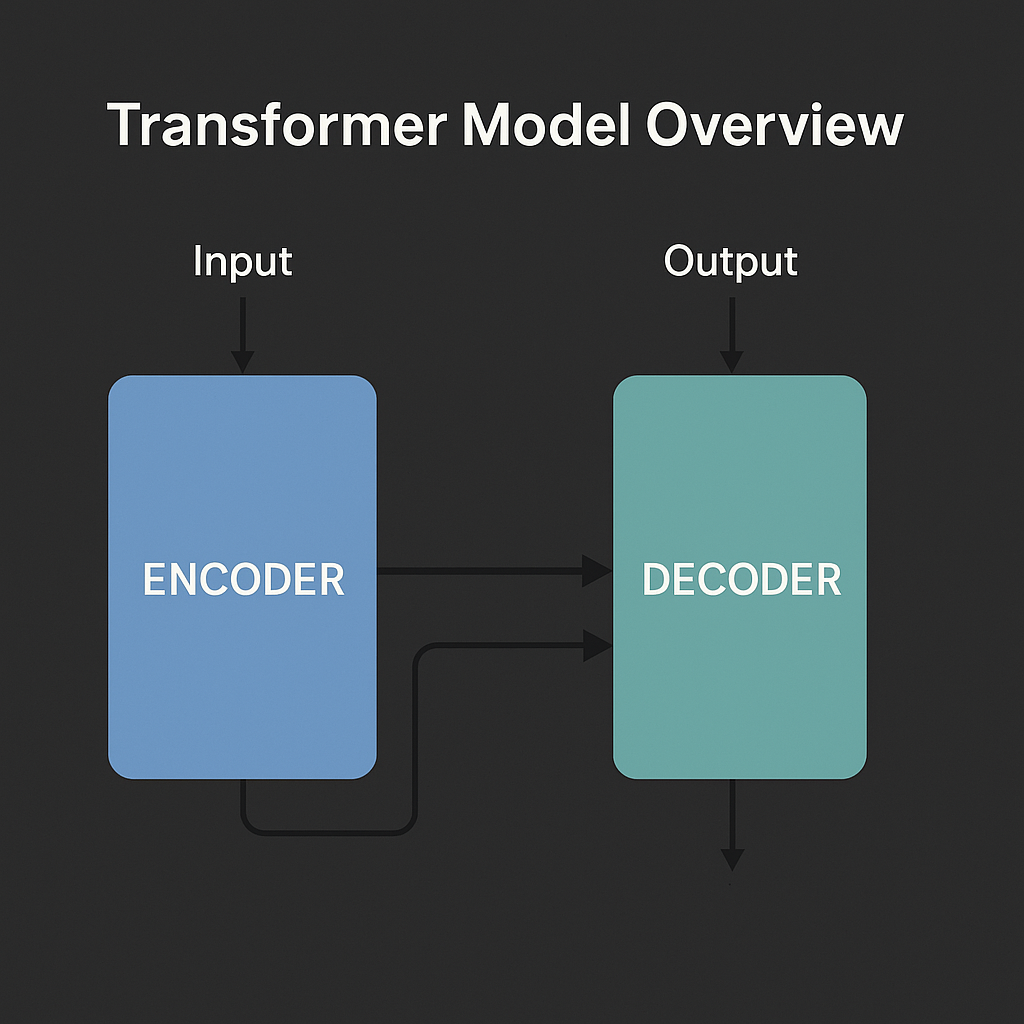
2017년 발표된 트랜스포머 모델은 LLM 발전의 전환점입니다. 이전 모델과 달리, 문장 전체를 한 번에 병렬로 처리하여 효율성을 크게 높였습니다.
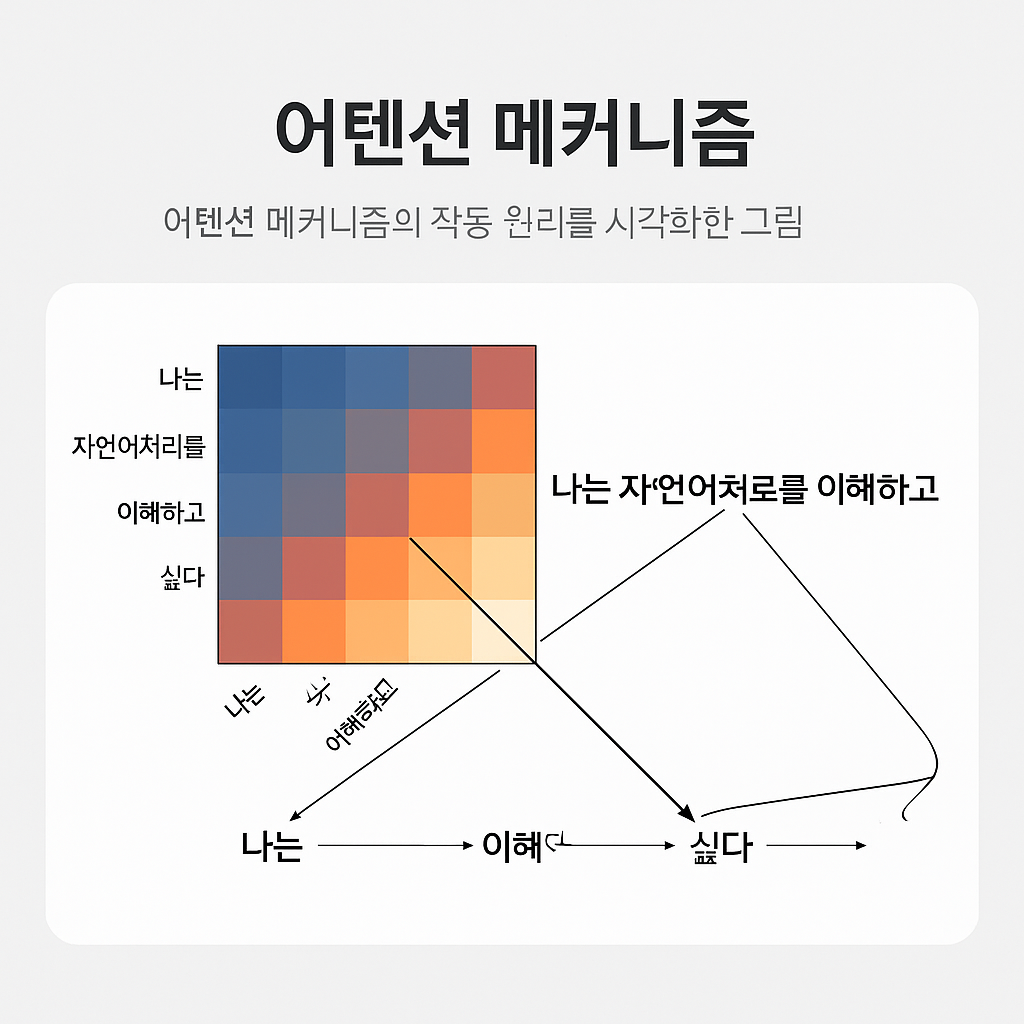
트랜스포머의 핵심은 어텐션 메커니즘입니다. 단어들을 숫자 벡터로 변환 후, 이 벡터들이 서로 정보를 주고받으며 문맥에 따라 각 단어의 의미를 동적으로 조정합니다. 예를 들어, '눈'이라는 단어는 문맥에 따라 '하늘에서 내리는 눈' 또는 '사람의 눈'으로 다르게 해석될 수 있습니다.
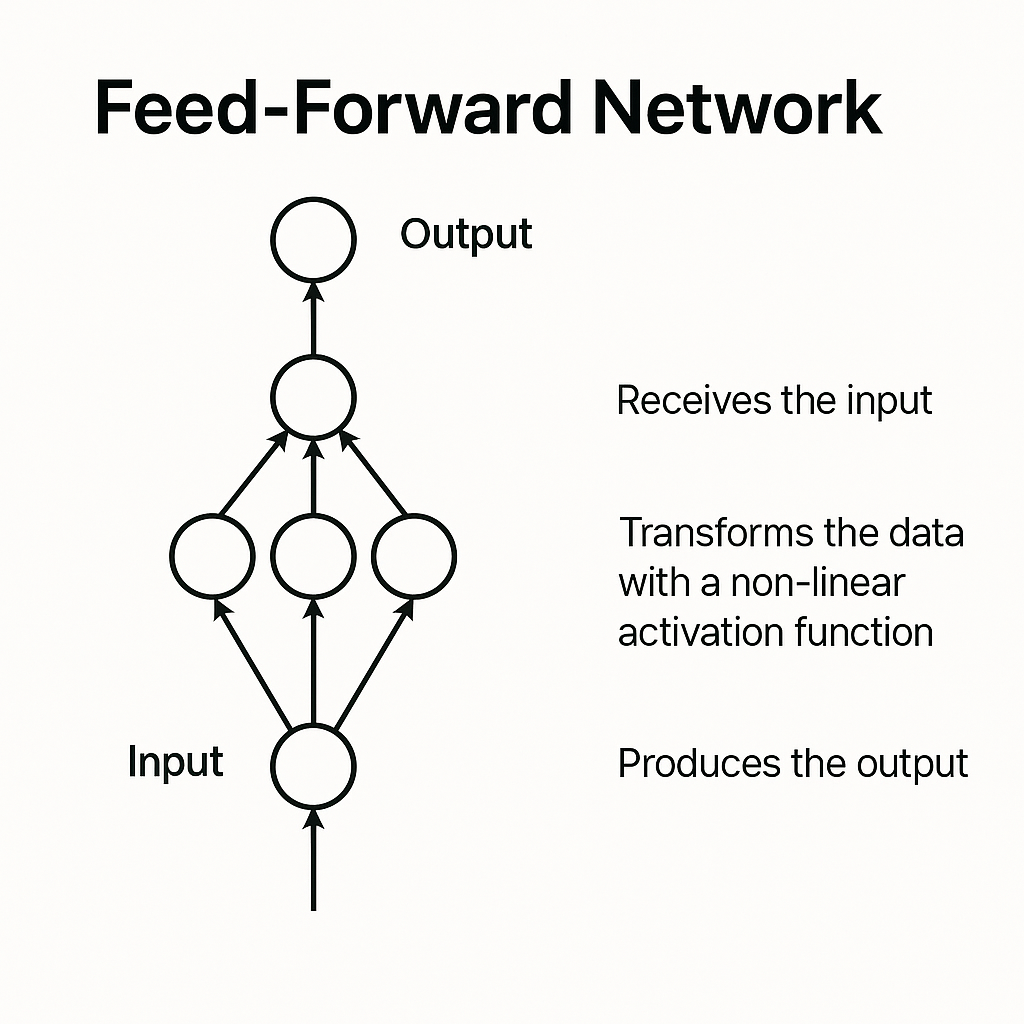
트랜스포머 내의 피드포워드 네트워크는 모델이 더 많은 언어 패턴을 학습하고 저장하도록 돕습니다. 어텐션과 피드포워드 연산을 여러 층에 걸쳐 반복하며, 단어 벡터는 문맥을 더욱 정교하게 반영합니다.
사전 훈련된 LLM은 RLHF(인간 피드백 기반 강화 학습) 등으로 더욱 개선됩니다. 사용자의 피드백을 통해 모델은 더 유용하고 선호되는 답변을 생성하도록 조정됩니다. 이를 통해 매우 자연스럽고 실용적인 텍스트 생성이 가능해집니다.

LLM은 수백억에서 수천억 개에 이르는 방대한 파라미터를 가집니다. 이 파라미터 값들이 모델의 예측을 결정합니다. GPT-3 학습 텍스트양은 인간이 2,600년 이상 읽어야 하는 분량이며, 훈련에는 막대한 연산 자원과 특수 GPU가 필수적입니다.
LLM의 구체적인 내부 작동 방식과 특정 예측의 이유는 여전히 설명하기 어려운 과제입니다 ('블랙박스' 문제). 설명 가능성(Explainability) 연구가 활발히 진행 중이며, 지속적인 발전을 통해 LLM은 더욱 강력하고 신뢰할 수 있는 도구가 될 것입니다.
